

How to use Python to access the data
Requirements
In order to interact with the TAP interface of xmmssc.aip.de you only require
python 3+ and pyvo 1+.
pip install pyvo>=1.0
It is always useful to print the version of the pyvo module you are using.
The old version of pyvo is the most common culprit of the non-working scripts.
from pkg_resources import parse_version
import pyvo
if parse_version(pyvo.__version__) < parse_version('1.0'):
raise ImportError('pyvo version must be at least than 1.0')
print('\npyvo version %s \n' % (pyvo.__version__,))
Authentication
After registration, you can access your API Token by clicking on your user name
in the right side of the naviagation bar and select API Token.
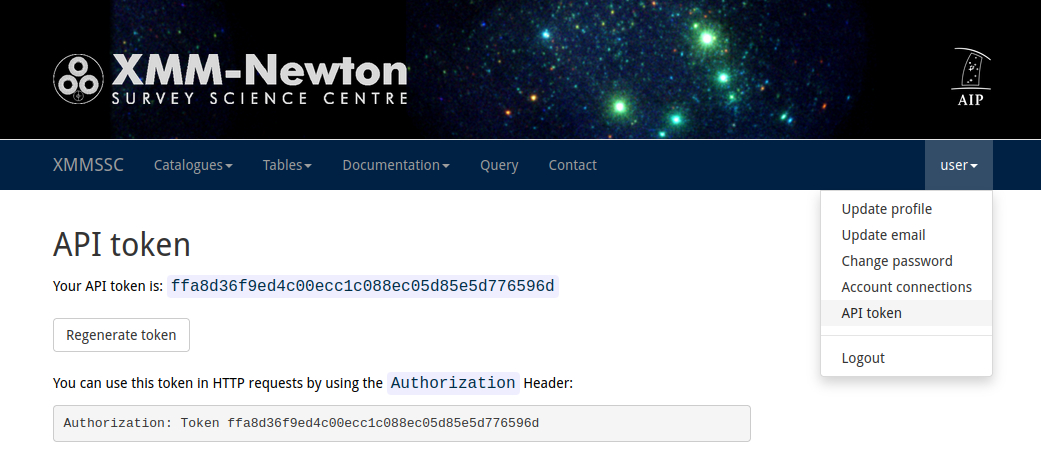
In the following code examples, replace <api-token> with your API token.
The
API Tokenidentifies you and provides access to the results tables of your queries.
The connection to the TAP service and authorization can be done in the following way
import requests
import pyvo
service_name = "XMMSSC@AIP"
url = "https://xmmssc.aip.de/tap"
token = 'Token <your-token>'
print('TAP service %s \n' % (service_name,))
# Setup authorization
tap_session = requests.Session()
tap_session.headers['Authorization'] = token
tap_service = pyvo.dal.TAPService(url, session=tap_session)
Short queries
Many queries last less than a few seconds. We call them short queries. The latter can be executed with synchronized jobs. You will retrieve the results interactively.
lang = "PostgreSQL"
query = '''-- Select the corresponding StackID for a given ObsID
SELECT "obs_id", "stack_id", "n_observations", "n_sources_stack"
FROM "xmm4_dr11s"."obslist"
WHERE obs_id LIKE '0002970401'
'''
tap_result = tap_service.run_sync(query, language=lang)
Remark: the
langparameter can take two values eitherPostgreSQLorADQLthis allows to access some featured present in the one or the other language for more details about the difference between both please refer : Documentation or to IOVA docs
The result tap_result is a so called TAPResults
that is essentially a wrapper around an Astropy votable.Table. For standard conversion
see the chapter Convert to various python types.
Remark: The query jobs delivered via TAP are also listed in the Query interface on the left hand side. The more detailed list can be viewed here.
Asynchronous jobs
For slightly longer queries, typically counting or larger selections (>10000 objects) a synchronized job will fail because of timeouts (from http protocol or server settings). This is why we provide the possibility to submit asynchronous jobs. These type of jobs will run on the server side, store the results such that you can retrieve them at a later time. They come in 2 flavors:
- 30 second queue
- 5 min queue
The 30 seconds queue
Most of the asynchronous queries will require less than 30 seconds, basically all queries without JOIN or CONE SEARCH.
Therefore, this queue is the default and should be preferred.
# Submit the query as an async job
query_name = "obs-list-for-given-stack"
lang = 'PostgreSQL' # ADQL or PostgreSQL
query = '''
-- Select all observations for a given StackID
SELECT "obs_id", "stack_id", "ra", "dec", "mjd_start", "mjd_stop", "obs_class"
FROM "xmm4_dr11s"."obslist"
WHERE "stack_id" = 374
'''
job = tap_service.submit_job(query, language=lang, runid=query_name, queue="30s")
job.run()
# Wait to be completed (or an error occurs)
job.wait(phases=["COMPLETED", "ERROR", "ABORTED"], timeout=30.0)
print('JOB %s: %s' % (job.job.runid, job.phase))
# Fetch the results
job.raise_if_error()
print('\nfetching the results...')
tap_results = job.fetch_result()
print('...DONE\n')
As for sync jobs, the result is a TAPResults object.
The 5 minutes queue
If you want to extract information on specific stars from various tables, you have to
JOIN tables. Your query may need more than a few seconds.
For that, the 5 minutes queue provides a good balance. It should be
noticed that for such a queue, the wait method should not be used to prevent
an overload of the server at peak usage. Therefore using the script with
the sleep() method is recommended.
# Submit the query as an async job
lang = 'PostgreSQL'
query_name = "low-bkg-obs"
query = '''
-- Select observations with very low background
SELECT "stack_id", "obs_id", "n_observations", "n_contrib_max",
"ra", "dec", "pn_bkg_cprob", "m1_bkg_cprob", "m2_bkg_cprob"
FROM "xmm4_dr11s"."obslist"
WHERE pn_bkg_cprob < 0.1
AND m1_bkg_cprob < 0.1
AND m2_bkg_cprob < 0.1
'''
job = tap_service.submit_job(query, language=lang, runid=query_name, queue="5m")
job.run()
print('JOB %s: SUBMITTED' % (job.job.runid,))
# Wait for the query to finish
while job.phase not in ("COMPLETED", "ERROR", "ABORTED"):
print('WAITING...')
time.sleep(120.0) # do nothing for some time
print('JOB ' + (job.phase))
# Fetch the results
job.raise_if_error()
print('\nfetching the results...')
tap_results = job.fetch_result()
print('...DONE\n')
Submitting multiple queries
Some time it is needed to submit several queries at one time. Either because the entire query may last longer than 5 minutes and you need to cut it in smaller parts, or because you need non JOIN-able information from various tables.
List of file queries
Sometimes it is useful to just send all .sql queries present in a directory. For such purpose you can use comments to provide the proper parameters.
Let us consider the file obs-1E3-5E3-src.sql
--- Select stack IDs with 1000 to 5000 sources
SELECT DISTINCT stack_id,
n_observations, n_sources_stack, n_contrib_max, ref_ra, ref_dec, area_est
FROM "xmm4_dr11s"."obslist"
WHERE "n_sources_stack" BETWEEN 1000 AND 5000
ORDER BY n_sources_stack
The language and queue are prescibed as comments. The query can then be submitted in a script like the following:
import glob
import os
# find all .sql files in current directory
queries_filename = sorted(glob.glob('./*.sql'))
print('Sending %d examples' % (len(queries_filename),))
# initialize test results
jobs = []
failed = []
# send all queries
for query_filename in queries_filename:
# read the .SQL file
with open(query_filename, 'r') as fd:
query = ' '.join(fd.readlines())
# Set language from comments (default: PostgreSQL)
if 'LANGUAGE = ADQL' in query:
lang = 'ADQL'
else:
lang = 'PostgreSQL'
# Set queue from comments (default: 30s)
if 'QUEUE = 5m' in query:
queue = '5m'
else:
queue = '30s'
# Set the runid from sql filename
base = os.path.basename(query_filename)
runid = os.path.splitext(base)[0]
print('\n> Query : %s\n%s\n' % (runid, query))
The rest of the submission process and retrieval can be done in any manner.
Downloading files from path results
Some queries do not return data but the urls of the files where the data are stored; examples are spectras, images or cubes. When your query returns a few file-paths it is possible to download them by hand, however it is usually more practical to download them automaticaly. Here is an example using python:
# specific imports
import os
import urllib
lang = "PostgreSQL"
query = '''
-- Request all resources related to stack_id 10
SELECT "ID", access_url, description
FROM "xmm4_dr11s"."datalink"
WHERE "ID" LIKE '%0010%'
'''
# Submit the query as Synchronous job (can be also done asynchronously)
tap_result = tap_service.run_sync(query, language=lang)
datalinks = tap_result.to_table()
# Set the local target directory for download
target_directory = './downloads/'
# create the target directory if it does not exist
os.makedirs(target_directory, exist_ok=True)
# build file url and download the files
for datalink in datalinks:
# extract name of the file
filename = os.path.basename(datalink['access_url'])
# set the target local file
local_file_path = os.path.join(target_directory, filename)
# download and save into target file
print("Downloaded {filename} into {target}".format(filename=filename, target=local_file_path))
urllib.request.urlretrieve(datalink['access_url'], local_file_path)
print('\nDone')
Convert result to various python types
The results obtained via the fetch_results() method returns a so
called TAPResults object. The latter is essencially a votable. In case you are
not familiar with votables, here are a few tricks to get back to some more general pythonic or astropy types.
Print data to screen
Print the data:
tap_results.to_table().pprint(max_lines=10)
It is important to notice the max_lines keyword, printing too many lines may crash a low-memory machine.
Show as html (in a browser):
tap_results.to_table().show_in_browser(max_lines=10)
It is important to notice the max_lines keyword, printing too many lines may crash a low-memory machine.
Show in a notebook (ipython, jupyter or jupyterlab):
tap_results.to_table().show_in_notebook(display_length=10)
It is important to notice the display_length keyword, printing too many lines may crash a low-memory machine.
Write data to file
Write the results to a VOTable
tap_results.votable.to_xml("filename.xml")
# or
tap_results.to_table().write("filename.xml", format='votable')
Write the results to FITs file
tap_results.to_table().write("filename.fits", format='fits')
Write the results to CSV file (not recommanded due to loss of metadata)
tap_results.to_table().write("filename.csv")
Convert to alternative format
Get a numpy array:
np_array = tap_results.to_table().as_array()
Get a Panda's DataFrame
df = tap_results.to_table().to_pandas()
Get the header of DataFrame
df.head()
Archiving your jobs
If you submit several large queries you may go over quota (currently, set to 1 GB per user). In order to avoid to get over quota you may consider archiving your jobs. Archiving removes the data from the server side but keeps the SQL query. This allows to resubmit a query at a later time.
Deleting (Archiving) a job with pyvo can be simply done that way:
job.delete()
Archiving all COMPLETED jobs
A nice feature of the TAP service is to retrieve all jobs that are marked as COMPLETED and archive them at ones. This can be done as follows:
# Archiving all COMPLETED jobs
# obtain the list of completed job_descriptions
completed_job_descriptions = tap_service.get_job_list(phases='COMPLETED')
# Archiving each of them
for job_description in completed_job_descriptions:
# get the jobid
jobid = job_description.jobid
# recreate the url by hand
job_url = tap_service.baseurl + '/async/' + jobid
# recreate the job
job = pyvo.dal.AsyncTAPJob(job_url, session=tap_session)
print('Archiving: {url}'.format(url=job_url))
job.delete() # archive job
Rerunning ARCHIVED jobs
Rerunning and retrieving results from a job that have been archived previously, can be achieved that way:
# Rerunning Archived jobs
# obtain the list of the two last ARCHIVED job_descriptions
archived_job_descriptions = tap_service.get_job_list(phases='ARCHIVED', last=2)
# rerunning the two last Archived jobs
for job_description in archived_job_descriptions:
# get jobid
jobid = job_description.jobid
# recreate the url by hand
job_url = tap_service.baseurl + '/async/' + jobid
# recreate the archived job
archived_job = pyvo.dal.AsyncTAPJob(job_url, session=tap_session)
# get the language (with a bit of magic)
lang = [parameter._content for parameter in archived_job._job.parameters if parameter._id == 'query_language'][0]
# extract the query
query = archived_job.query
# resubmit the query with corresponding parameters
job = tap_service.submit_job(query, language=lang, runid='rerun', queue='30s')
print('%(url)s :\n%(query)s\n' % {"url": job_url, "query": query})
# start the job
try:
job.run()
except pyvo.dal.DALServiceError:
raise ValueError("Please check that the SQL query is valid, and that the SQL language is correct.")
The retrieval of the results is done alike explained above.
If you prefer, you can also filter for a given runid.
# Filtering by runid
target_runid = 'low-bkg-obs'
# obtain the list of completed job_descriptions
archived_job_descriptions = tap_service.get_job_list(phases='ARCHIVED')
for job_description in archived_job_descriptions:
# select the job with runid fitting target_runid
if job_description.runid == target_runid:
# get jobid
jobid = job_description.jobid
# recreate the url by hand
job_url = tap_service.baseurl + '/async/' + jobid
# recreate the archived job
archived_job = pyvo.dal.AsyncTAPJob(job_url, session=tap_session)
# get the language (with a bit of magic)
lang = [parameter._content for parameter in archived_job._job.parameters if parameter._id == 'query_language'][0]
# extract the query
query = archived_job.query
# resubmit the query with corresponding parameters
job = tap_service.submit_job(query, language=lang, runid='rerun', queue='30s')
print('%(url)s :\n%(query)s\n' % {"url": job_url, "query": query})
# start the job
try:
job.run()
except pyvo.dal.DALServiceError:
raise ValueError("Please check that the SQL query is valid, and that the SQL language is correct.")